Using AgentQL and Pipedream to Fix Missing RSS Feeds

Last week I blogged about how I used AgentQL to scrape a web page, this blog to be precise, into pure data. If you don't remember, AgentQL lets you pass a simple query string that is run against a web page and parsed into data. So for example, I was able to use this query on my home page to get a list of entries in pure data:
{
blogposts[] {
url
title
date
}
}
The REST API was incredibly easy, and I demonstrated in BoxLang how I could use AgentQL to turn my blog's home page into a much simpler, smaller, HTML version. This of course begs the question, how else could we transform it? What about creating a RSS feed for a blog that doesn't have one!
The Blog In Question
The blog I was trying to create an RSS feed from is on Google's developer blog, specifically focused on the Gemini AI product: https://developers.googleblog.com/en/search/?product_categories=Gemini. I did not notice an RSS mentioned in the UI, and when I did a View Source and looked for xml, feed, etc., I wasn't able to find it. To be clear, they may indeed have an RSS feed and I just don't see it. But that's ok, it wouldn't have stopped me from building this demo anyway. ;)
Updating My Query
As I showed above, it's relatively simple to write the AgentQL query to get a list of blog posts, but I knew that if I wanted to create an RSS feed I'd need the date in a different format. My original query returned the date as you see on the page, July 22, 2025 for example. AgentQL lets you pass 'hints' to the query, so I tried a few things and eventually ended up here:
{
blogposts[] {
url
title
date(convert to time since epoch)
}
}
I tested this using their browser extension and it worked fine, since of course I can convert epoch to real time in my head. Here's part of the response (I removed a few entries to keep the output shorter):
{
"blogposts": [
{
"url": "https://developers.googleblog.com/en/gemini-25-flash-lite-is-now-stable-and-generally-available/",
"title": "Gemini 2.5 Flash-Lite is now stable and generally available",
"date": 1753180800000
},
{
"url": "https://developers.googleblog.com/en/conversational-image-segmentation-gemini-2-5/",
"title": "Conversational image segmentation with Gemini 2.5",
"date": 1753094400000
},
{
"url": "https://developers.googleblog.com/en/veo-3-now-available-gemini-api/",
"title": "Build with Veo 3, now available in the Gemini API",
"date": 1752835200000
},
{
"url": "https://developers.googleblog.com/en/gemini-25-for-robotics-and-embodied-intelligence/",
"title": "Gemini 2.5 for robotics and embodied intelligence",
"date": 1751366400000
}
]
}
Cool, now I've got a good query, time to build a workflow.
Building the Workflow with Pipedream
I went, of course, to Pipedream, my workflow service of choice. (Although I've been using n8n as well lately and will have some blog content on it soon.) Here's a visual representation of the workflow I created:
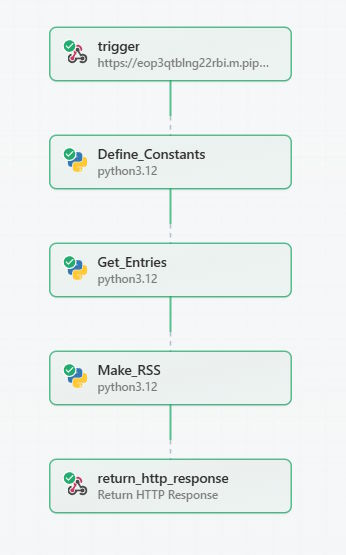
The first item in the workflow is simply a HTTP trigger. This gives me a URL I can use for the RSS feed.
The second item is a bit of Python code meant to define variables I use later in the flow. Pipedream supports environment variables of course, but these values are more like constants. Here they are:
def handler(pd: "pipedream"):
# I'm just used to set some values used a few times in the later steps
# blogUrl is the url to hit obviously,
# title and desc are used in the RSS generation area. blogTZ adds a tz to dates
return {
"blogUrl": "https://developers.googleblog.com/en/search/?product_categories=Gemini",
"title": "Google Gemini Blog Enties",
"description": "AI Generated RSS Feed for Google Gemini Blog",
"blogTZ":"America/Los_Angeles"
}
As the comment says, the first value is the URL I'm parsing and the next three are used when generating the RSS.
The third step in my flow uses AgentQL, but also makes use of a Pipedream feature, Data Stores, for a lightweight key/value caching system. In the step itself, I configured it to use a particular store, and I then reference it in the code. Here's the entire step:
import os
import requests
def handler(pd: "pipedream"):
# do we have a good cache?
cache = pd.inputs["data_store"]
cachedData = cache.get("entries")
if cachedData:
print("cache used")
return cachedData
AGENTQL_API_KEY = os.environ.get("AGENTQL_API_KEY")
URL = pd.steps["Define_Constants"]["$return_value"]["blogUrl"]
query = """
{
blogposts[] {
url
title
date(convert to time since epoch)
}
}
"""
body = {
"query":query,
"url":URL
}
headers = {
"X-API-Key":AGENTQL_API_KEY,
"Content-Type":"application/json"
}
res = requests.post("https://api.agentql.com/v1/query-data", json=body, headers=headers)
entries = res.json()["data"]["blogposts"]
cache.set("entries", entries, ttl=3600)
return entries
The cache check is up on top and I print out a message just to confirm the cache is working. At the bottom of the step, you can see where I store the value with an hour cache. To be honest, I could probably cache for a heck of a lot longer. The rest of the code is simply me hitting AgentQL's REST API, much like the code in my previous blog post, except in Python now.
The fourth step actually generates the RSS. For that I make use of a Python library called python-feedgen. For the most part, this is relatively simple, except for two small things. Let me share the code first:
from feedgen.feed import FeedGenerator
from datetime import datetime
from pytz import timezone as pytz_timezone
def handler(pd: "pipedream"):
URL = "https://developers.googleblog.com/en/search/?product_categories=Gemini"
fg = FeedGenerator()
fg.title(pd.steps["Define_Constants"]["$return_value"]["title"])
fg.description(pd.steps["Define_Constants"]["$return_value"]["description"])
fg.link(href=pd.steps["Define_Constants"]["$return_value"]["blogUrl"])
timezone = pytz_timezone(pd.steps["Define_Constants"]["$return_value"]["blogTZ"])
for entry in pd.steps["Get_Entries"]["$return_value"]:
fe = fg.add_entry()
fe.id(entry["url"])
fe.title(entry["title"])
fe.link(href=entry["url"])
date = datetime.fromtimestamp(entry["date"])
localized_dt = date.astimezone(timezone)
fe.published(localized_dt)
# not sure why they return a byte string
tempStr = fg.rss_str()
string_data = tempStr.decode("utf-8")
return string_data
Ok, for the most part, this looks relatively easy, right? The first issue I ran into however was that I needed my datetime value to have a timezone. I kinda thought the Python datetime value I got from converting the epoch time would have a "natural" timezone, but it did not. I Googled, saw the pytz library, and basically copied over the code it used. The actual timezone is back in my Define_Constants step and was a bit arbitrary. I figured Google is in California so I'd used that timezone.
Now, the last few lines are the most confusing. The rss_str returns a binary, not "regular" string of XML. I have no idea why. There's probably a good reason and I asked on their repo about it. But it took all of one additional line to make it a string.
And that's it! The last step is just a built-in Pipedream action to output an HTTP response and for that, I used the result of the last step. I also added the appropriate header:
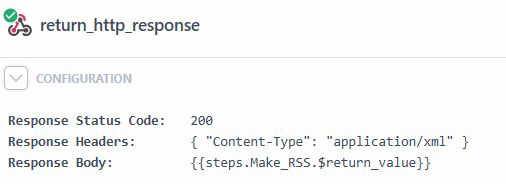
And that's it - I mean for real this time. You can see the generated RSS here: https://eop3qtblng22rbi.m.pipedream.net/. I do wish it returned a bit quicker. I could, in theory, cache the RSS string instead of the data and return earlier, and it may help, but I'm fine with it now. If you are a Pipedream user and want to see the raw source of the flow, you can find it here: https://github.com/cfjedimaster/General-Pipedream-AI-Stuff/tree/production/rss-from-gemini-blog-p_G6C5QeB
Photo by Ella Ivanescu on Unsplash