Building a Document Q&A System with Google Gemini

Document summarization is a powerful and pretty darn useful feature of generative AI, but a proper "question and answer" system can really enable users to interact with a document. This is why you see various document viewing apps, like Acrobat, adding these features to their programs. I thought I'd take a look at building such a system via a simple web app to see how difficult it would be, and honestly, it wasn't that bad. Having this in your own web app, versus an external vendor, gives you more control over the experience as well. Here's what I built.
The Stack
The web app lets you drag and drop a PDF into the page, it then renders a preview of the PDF on the left and gets the summary on the right-hand side. After the summary is generated, you can then ask various questions via a chat interface.
- For the web app, I'm using Flask, a Python web framework.
- For displaying the PDF, I'm using EmbedPDF. This is a free tool to render PDFs on the web and it's dang cool. The only issue with it currently is a lack of documentation, but that's coming very soon.
- Once again, I'm using the Google Gemini API for my generative AI features. I know I sound like a broken record, but it's honestly been the easiest GenAI system I've used and with a free tier, it's great for building proof of concepts like what I'm sharing today.
The Application
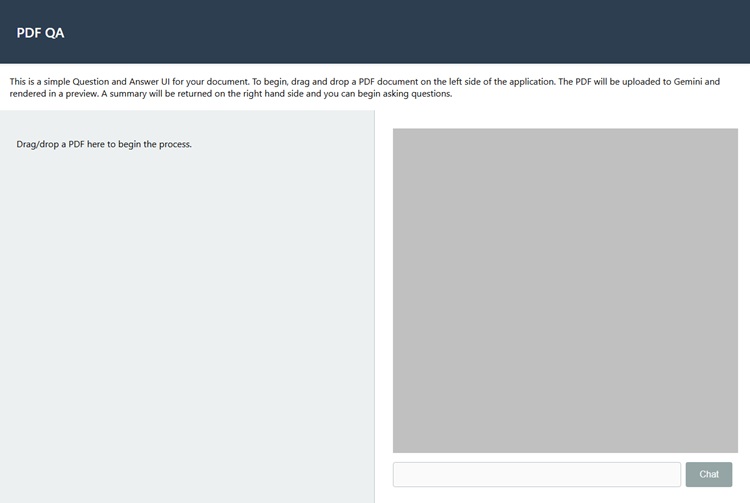
Here's how the application looks when you initially start it up:
Dragging a PDF onto the left side will fire up EmbedPDF to render it:
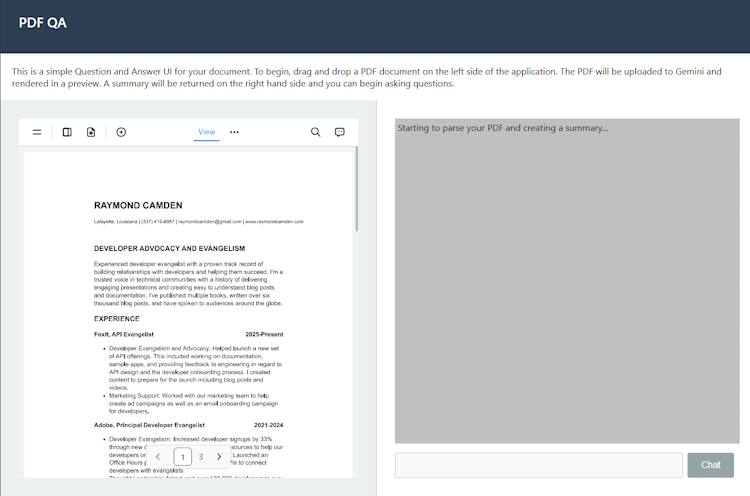
In the screenshot above, you can see it mentioning that the summary process is starting. Depending on the size of your document, this can take a bit of time, but once done, it's rendered automatically:

I used my resume for input, and the summary was spot on. The input/chat button UI is automatically enabled at this point, and you can start asking questions. For example, where did I work in 2020? The response was:
In 2020, Ray worked at HERE Technologies as a Lead Developer Evangelist (2019-2021).
Accurate! How about, "Does Ray have skills in C#?"
Based on the provided resume, Ray (Raymond Camden) does not list C# as one of his skills.
His listed skills are:
* Developer evangelism and advocacy
* Technical writing and editing
* API development and usage
* Generative AI
* JavaScript and the Web Platform
* Node.js
* Python
* Public speaking
He also mentions working with Java and Node.js in his experience at American Express,
and ColdFusion in his publications, but C# is absent.
I then asked, "does ray live in the united states?". I don't say I do in the resume, but I do list my city and state. The response was:
Yes, Raymond Camden lives in the United States. His resume states his location
as Lafayette, Louisiana.
The Code
I'm going to share all the code via a GitHub link at the end, so I'll focus on the most interesting parts. On the front end, it's mainly just JavaScript to handle DOM updates and such. The only real cool part is the "drop and render PDF" aspect via the EmbedPDF library. Here's a bit of that code to show how it's done:
import EmbedPDF from 'https://snippet.embedpdf.com/embedpdf.js';
// then later ($dropZone is the DIV you can drop crap
$dropZone.addEventListener('drop', async e => {
e.preventDefault();
let files = e.dataTransfer.files;
if(!files) return;
if(files[0].type !== 'application/pdf') {
alert('Drop PDF files only, please.');
return;
}
pdf = files[0];
// ok, we begin by kicking off the rendering process
$instructions.parentNode.removeChild($instructions);
$pdfViewer.style.display = 'block';
const viewer = EmbedPDF.init({
type: 'container',
target: document.getElementById('pdf-viewer'),
src: URL.createObjectURL(pdf),
plugins: {
zoom: {
defaultZoomLevel: 'fit-width',
}
}
});
// stuff removed
});
After the PDF is rendered, I then send it to the backend. In Flask, I'm just doing this:
PDF = './input.pdf'
# later....
@app.route('/upload', methods=['POST'])
def upload_file():
# not sure if this extra check is necessary, but extra is extra
if request.method == 'POST':
f = request.files['pdf']
f.save(PDF)
return { "status": "Ok" }
Right away little red lights should be flashing in your head, alarms going off, people panicking in general...

Obviously in a "real" app, you would have multiple users sending up files. You don't want any input dropping in web root (although in Flask, this wouldn't load) nor do you want to use the same filename. Also, you could easily take the binary data of the PDF sent and pass it immediately to Gemini for uploading. You would then need to associate the corresponding file object with the current user.
Oncee stored and the front-end gets that Ok, I then fire off a network call to do the summary:
@app.route('/summary')
def summarize_pdf():
result = gemini.summarize(PDF)
return { "result": result }
I've got a Gemini Python package that handles making these calls. I'll share it in a second. Once the summary is returned and chat is enabled, this is another simple Flask route:
@app.route('/chat', methods=['POST'])
def chat_pdf():
if request.is_json:
data = request.json
print(f"Sending {data.get('input')} to gemini")
result = gemini.chat(PDF, data.get('input'))
return { "result": result }
The Gemini package handles uploading the document, doing the summary, and ad hoc chat requests:
from google import genai
from pydantic import BaseModel
import os
class Gemini:
def __init__(self):
self.client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
self.doc = None
def summarize(self, path):
# In theory, this is dumb, we upload once in our POC
if self.doc is None:
print("Uploading PDF")
self.doc = self.client.files.upload(file=path)
prompt = """
Please act as an expert summarizer. Analyze the provided PDF document and create a concise and comprehensive summary of its key contents. Your summary should focus on the main arguments, conclusions, and any significant data or findings. It should be written in a clear, neutral tone and be easy for a non-expert to understand.
"""
response = self.client.models.generate_content(
model='gemini-2.5-flash',
contents = [prompt, self.doc],
config = {
'response_mime_type': 'text/plain',
}
)
return response.text
def chat(self, path, prompt):
# ditto, also dumb, can't get here until you summarize, but whatev
if self.doc is None:
print("Uploading PDF")
self.doc = self.client.files.upload(file=path)
response = self.client.models.generate_content(
model='gemini-2.5-flash',
contents = [prompt, self.doc],
config = {
'response_mime_type': 'text/plain',
}
)
return response.text
It's pretty short as the Gemini Python SDK handles most stuff. I'm missing error handling of course but... nothing goes wrong, ever, right?
What Else?
So as I promised, here's the GitHub link to the complete application: https://github.com/cfjedimaster/ai-testingzone/tree/main/pdf_qa
There are multiple ways this could be improved. For example:
- If this tool were built for a particular company, you may have a particular type of document you will almost always be working with. That information could be fed to the AI model via a system instruction to help it answer questions better.
- The chat log could be made exportable and shareable.
- Of course, if you want to get real fancy, you could enable speech recognition and simply talk to the browser to interrogate the document.
- The PDF embed library I'm using, which still needs some documentation, will eventually (or should eventually) support the ability to navigate to pages. You could set up the Gemini prompt to return metadata about where in the document things are found and then automatically navigate to those pages. That would be incredibly useful in a large document. Most likely this could also support searching and highlighting text.
Let me know what you think and leave me a comment below.