Working with Algolia's Crawler

I've been using Algolia on my blog for a while now. It's an excellent search solution for the Jamstack and I absolutely recommend it, especially for sites where the size means Lunr may not be appropriate. While I like Algolia a lot, I haven't really dug terribly deep into it. I went through multiple iterations of my implementation here to help deal with the size of my content and so forth, but outside of that, I kept the actual search experience nice and simple. This week, I gave a talk at the Jamstack_Berlin user group on search options for the Jamstack and that's got me thinking more about both Lunr and Algolia. One of the things I've wanted to play with for quite some time is their Crawler product. While I didn't have time to research it before the presentation, I've had time to check it out and I thought I'd share my findings.
Before I begin, note that this feature is not available on the free tier. I think that's totally fair as it's really powerful and flexible (as I hope you'll see below), but I just wanted to be sure my readers were aware. Honestly, it's a bit hard to tell from their pricing page that Crawler isn't available for free, so please keep that in mind. I missed this, but there is a free version of this for open source projects, one already being used by many projects. This is called DocSearch and you find out more here: https://docsearch.algolia.com/
Getting Started
Assuming you have an Algolia account, you begin by clicking "Data sources" in the dashboard. If you are not on the free tier, you should see Crawler as a navigation item:
Doing so will take you - oddly - to this:

So... one of the weird things about Crawler is that it's not properly integrated into the main Algolia dashboard. As I said... weird. But honestly it's no big deal. I mainly bring it up so as to prepare you for the odd jump. The UI for Crawler is all easy to use (and really well done), but looks a bit like a different design team worked on it.
I decided to test Crawler on an old site I had, ColdFusion Cookbook. I converted this site to Jamstack a while back but more recently updated it to use Eleventy. As part of that conversion, I removed the previous search engine (which I think was a Google Programmable Search Engine) and decided I'd use the Algolia Crawler as a replacement.
Once logged into the Crawler dashboard, you're presented with a list of your existing implementations.

This will be empty at first but you can click to create a new one. I did so and entered a name and starting URL:

In the next step, they check for robots.txt and a sitemap URL. Notice how if you don't have one they can find automatically, you can enter one. This is not required though:
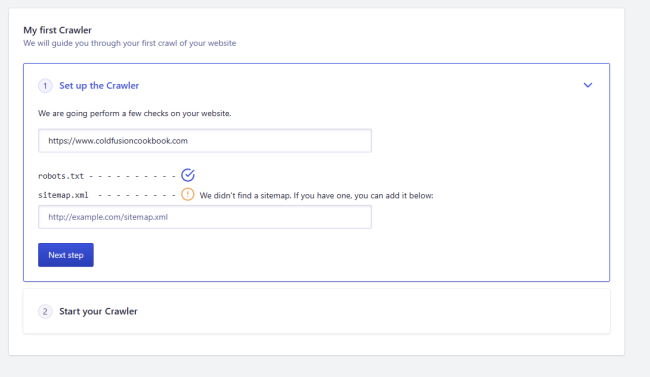
After this step, you can start the process. In the screenshot below, note the limit of 100 URLs. I'll explain how we correct this later.

I've mentioned before how while it was a bit jarring that the dashboard wasn't integrated with the rest of Algolia and the general theme didn't match, I really liked how the Crawler admin was built. Below you can see an example of this. As the crawler starts working, you get live updates and even see sample data as it's ingested.

When done, you get a summary of the total records and any errors. Right away, I noticed a problem. 31 records didn't make sense. The site had 151 content entries, so given that plus miscellaneous pages, I expected a number above that... ignoring for a moment that it said it would cap out at 100.
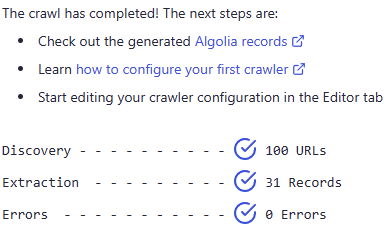
Ok, so what went wrong? Actually something great. Turns out I had something misconfigured on my site at Netlify. This issue caused content to load just fine, but it was redirecting from the proper URL (/something.html) to an alias (/something). The thing is - the content looked fine to my eyes, but Algolia was seeing the redirects and not indexing them. While maybe that's something you can configure with the crawler, I really wanted to correct it instead. I corrected the problem on the Netlify site and confirmed Algolia could pick up the changes.
After every crawler, Algolia will send you an email report:

Notice how it suggests setting up a schedule. I'll talk about that in a bit too.
So, once the crawl is done, you end up with two new indexes. Remember this will be back in the 'regular' dashboard, but you can then do test searches, look at your data, and so forth.

Here's an example record from my index. This was all done by the crawler and while I could modify the behavior, I love that it seemed to correctly parse everything perfectly. For example, the content field has UI and stuff stripped away. Algolia knew - for the most part - to avoid non-essential content. I say "most part" as it did pick up a bit of text from the right-hand side.

At this point, I was pretty happy and decided to look at fixing the cap of one hundred items. Back in the Crawler UI, you can do so via the "Editor" link, which pops open a JavaScript object:

While on one hand I kinda worry about non-technical people having to edit here, I was really blown away by the level of configuration here. It's freaking amazing. From what I can see, I could absolutely correct the issue I saw with some of the nav being included in the content - I'd just need to modify the code a bit. Also, I simply changed maxUrls to be 200 to fix the cap of 100 entries. It may be a bit hard to see in the screenshot, but the API key is blurred out in the editor automatically. I didn't do that for my screenshot.
As I know it's a bit hard to read, here's the code. Note that this is also where you supply a schedule:
new Crawler({
appId: "WFABFE7Z9Q",
apiKey: "--------------",
indexPrefix: "crawler_",
rateLimit: 8,
maxUrls: 200,
startUrls: ["https://www.coldfusioncookbook.com"],
sitemaps: [],
saveBackup: true,
ignoreQueryParams: ["source", "utm_*"],
schedule: "every 1 day at 3:00 pm",
actions: [
{
indexName: "ColdFusion Cookbook",
pathsToMatch: [
"https://www.coldfusioncookbook.com/**",
"https://coldfusioncookbook.com/**",
],
recordExtractor: ({ url, $, contentLength, fileType }) => {
return [
{
objectID: url.href,
url: url.href,
hostname: url.hostname,
path: url.pathname,
depth: url.pathname.split("/").length - 1,
contentLength,
fileType,
title: $("head > title").text(),
keywords: $("meta[name=keywords]").attr("content"),
description: $("meta[name=description]").attr("content"),
type: $('meta[property="og:type"]').attr("content"),
image: $('meta[property="og:image"]').attr("content"),
headers: $("h1,h2")
.map((i, e) => $(e).text())
.get(),
content: $("p").text(),
},
];
},
},
],
initialIndexSettings: {
"ColdFusion Cookbook": {
searchableAttributes: [
"unordered(keywords)",
"unordered(title)",
"unordered(description)",
"unordered(headers)",
"url",
],
customRanking: ["asc(depth)"],
attributesForFaceting: ["fileType", "type"],
},
},
});
By the way, you know how I said the online editor obscured the key. When I added a schedule, it did this:

I know I keep saying it, but damn is that well done. I just can't express how much I appreciate that little tooltip there.
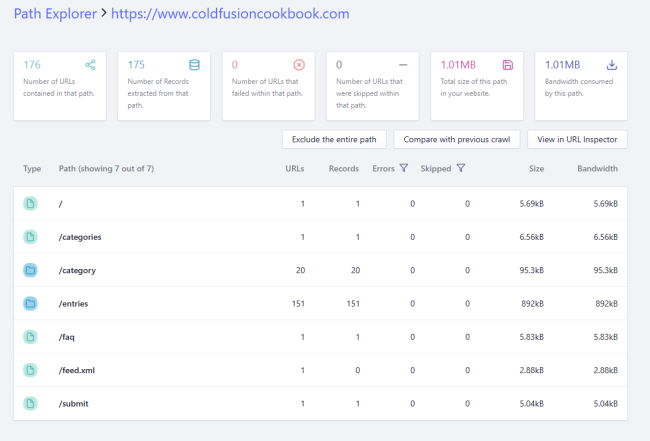
So what else is there? In the Crawler dashboard, you've got tools to inspect URLs and monitoring. There's a data analysis tool that looks for issues (none were found for me after fixing my Netlify issues) and a cool "Path Explorer":
All in all... just an incredibly impressive experience. For the actual search, since it's just another Algolia index, I copied the code I used from my search here, removed Vue.js because it wasn't necessary, and built it out like so:
---
title: Search
layout: main
headertext: Search for content here!
---
<h3>Search</h3>
<p>
<input type="search" id="searchField"> <input type="button" id="searchButton" value="Search">
</p>
<div id="resultsDiv"></div>
<script src="https://cdn.jsdelivr.net/npm/algoliasearch@4/dist/algoliasearch-lite.umd.js"></script>
<script>
document.addEventListener('DOMContentLoaded', init, false);
let searchField, searchButton, client, index, resultsDiv;
function init() {
searchField = document.querySelector('#searchField');
searchButton = document.querySelector('#searchButton');
resultsDiv = document.querySelector('#resultsDiv');
client = algoliasearch('WFABFE7Z9Q', 'd1c88c3f98648a69f11cdd9d5a87de08');
index = client.initIndex('crawler_ColdFusion Cookbook');
let qp = new URLSearchParams(window.location.search);
if(qp.get('searchterms')) {
searchField.value = qp.get('searchterms');
search();
}
searchButton.addEventListener('click', search, false);
}
async function search() {
let s = searchField.value;
console.log('search for',s);
searchButton.setAttribute('disabled', 'disabled');
let resultsRaw = await index.search(s,{
attributesToRetrieve:['title', 'url'],
attributesToSnippet:['description'],
hitsPerPage: 50
});
console.log('results', resultsRaw);
let results = resultsRaw.hits;
let result = '';
if(results.length === 0) {
result = '<p>Sorry, but there were no matches for this term.</p>';
} else {
result = `<p>There were ${results.length} hit(s) for this term:</p><ul>`;
results.forEach(r => {
result += `<li><a href="${r.url}">${r.title}</a></li>`;
});
result += '</ul>';
}
resultsDiv.innerHTML = result;
searchButton.removeAttribute('disabled');
}
</script>
If you want, you can run it yourself here: https://www.coldfusioncookbook.com/search
Let me know what you think, and if you're using Algolia Crawler as well, I'd love to know!
Photo by Ray Hennessy on Unsplash