Scraping URLs from a Sitemap File
Yesterday I wrote about a person who is stealing my content (and others) for their blog. As part of my process to fight against this jerk I had to file a DCMA claim that includes the URLs of the offending content. In order to get all the URLs, I had to work with their site map, copy the content, and use XPath to get the URL values. I decided to whip up a quick tool that would automate the entire process.
The app is pretty simple. You enter a URL of a sitemap, hit the button, and stand back while it works:
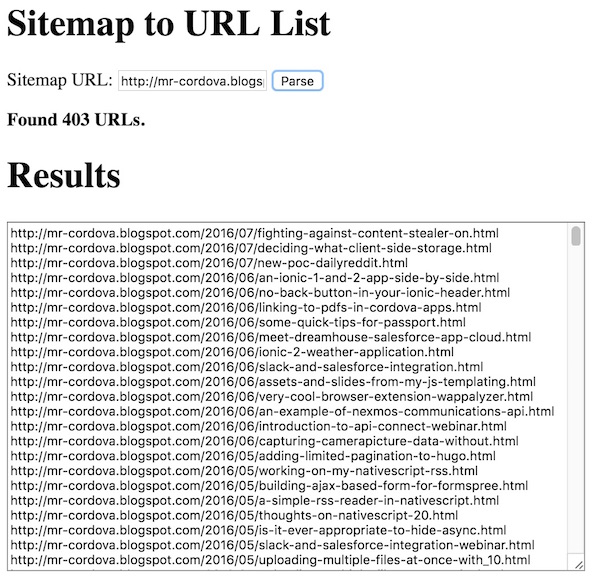
The code is pretty simple. I use Yahoo Query Language to run an XPath on the sitemap. I can't just look for URLs though as a sitemap can contain a list of sitemaps instead of URLs. So for example, the asshat stealing my content has a sitemap that looks like this:
<?xml version='1.0' encoding='UTF-8'?>
<sitemapindex xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<sitemap>
<loc>http://mr-cordova.blogspot.com/sitemap.xml?page=1</loc>
</sitemap>
<sitemap>
<loc>http://mr-cordova.blogspot.com/sitemap.xml?page=2</loc>
</sitemap>
<sitemap>
<loc>http://mr-cordova.blogspot.com/sitemap.xml?page=3</loc>
</sitemap>
</sitemapindex>
So my code needs to see if this type of data exists in the sitemap first. Here's the entire code for how I parse the sitemap. There's a bit more code (feel free to view source at the demo) for DOM stuff, but this is the important part.
function parseSitemap() {
var url = $siteMapURL.val();
if($.trim(url) === '') return;
$results.val('');
$status.html('<i>Trying to parse the sitemap.</i>');
console.log('try to parse '+url);
/*
A sitemap may consist of a list of sitemaps. So step one is to see
if that exists. We'll create an array for all the sitemaps we need to parse.
For simple sitemaps w/o a list of others, the array will have one item.
*/
var sitemaps = [];
var query = "https://query.yahooapis.com/v1/public/yql?q=select%20*%20from%20html%20where%20url%20%3D%20'" + url + "'%20and%20xpath%3D'%2F%2Fsitemap'&format=json&diagnostics=true&callback=";
$.get(query).then(function(res) {
if(res.query.diagnostics && res.query.diagnostics.url[0]["http-status-code"] === "404") {
$status.html('<b>This URL appears to be invalid.</b>');
return;
} else if(res.query.count > 0) {
for(var i=0;i<res.query.count;i++) {
sitemaps.push(res.query.results.sitemap[i].loc);
}
} else {
sitemaps[0] = url;
}
console.log('sitemaps to handle is '+sitemaps);
$status.html('<i>Gathering data for sitemaps URLs.</i>');
var promises = [];
sitemaps.forEach(function(sitemap) {
var def = $.Deferred();
var query = "https://query.yahooapis.com/v1/public/yql?q=select * from html where url = '"+sitemap+"' and xpath='//url/loc'&format=json&diagnostics=true&callback=";
$.get(query).then(function(res) {
def.resolve(res.query.results.loc);
});
promises.push(def);
});
$.when.apply($,promises).done(function() {
console.log('totally done getting urls');
var results = [];
for(var i=0;i<arguments.length;i++) {
for(var x=0;x<arguments[i].length;x++) {
results.push(arguments[i][x]);
}
}
console.log('found '+results.length + ' urls');
$status.html('<b>Found '+results.length + ' URLs.</b>');
$results.val(results.join('\n'));
});
});
}
As you can see, I end up using promises (jQuery-style) to handle the case where multiple sitemaps exist. For each unique sitemap "set", I run a YQL on it to fetch the URLs. At the end I have an array of URLs you can copy and paste. Yeah, the code is a bit crap, but it works well so far.
You can run the demo yourself here: https://static.raymondcamden.com/demos/2016/07/index.html