On my blog, I write my entries in pure HTML. WordPress supports a Visual editor too, but I like to write my HTML tags by hand. That's how I've done it for the past twenty years and that's how God intended me to write HTML. (Joking, honestly.) What's nice is that I can leave out some tags, like paragraph markers, and WordPress will handle that for me. I typically just worry about italics, bold, and links.
Despite having worked with web pages since dinosaurs used FrontPage, I still screw up from time to time. My typical mistake is either not closing a tag: <i>Foo<i> or closing the wrong tag: <i>Foo</b>
I've often wondered - is there some way to test for this type of mistake on the client side?
Obviously you could use regex to check for the cases I described above, but regex can get messy. That and as much as I appreciate the power of regex I'd rather avoid it. Also, it wouldn't handle a case like this: <stron>Bold!</stron>.
Someone on Twitter (I forget who and I'm being too lazy to scroll through my Notifications panel) suggested DOMParser, but when I tried that I could find no way to detect invalid/broken HTML when passed to the API. It is entirely possible I was doing it wrong, but nothing really stood out.
I then had an idea - what if I tried the W3C Validator service? I use it for my Brackets extension (which I'll be rewriting to Visual Studio Code the second they release extension support) and it works well enough there, maybe I could use it in code? Here is what I came up with as a proof of concept.
<!doctype html>
<html>
<head>
<title>Proper Title</title>
<style>
</style>
</head>
<body>
<form id="myForm" method="post">
<textarea id="content" cols="50" rows="20"></textarea>
<p/>
<input type="submit">
</form>
<script type="text/javascript" src="http://ajax.googleapis.com/ajax/libs/jquery/2.0.3/jquery.min.js"></script>
<script>
var W3CURL = "https://validator.w3.org/nu/?out=json&level=error";
$(document).ready(function() {
$("#myForm").on("submit", function(e) {
e.preventDefault();
var html = $("#content").val();
if(html === '') return;
//wrap html into a proper body
html = "<!DOCTYPE html>\n<html><head><title>Test</title></head><body>" + html + "</body></html>";
$.ajax({
url:W3CURL,
data:html,
cache:false,
contentType:"text/html; charset=utf-8",
processData:false,
type:"POST",
success:function(data) {
console.dir(data);
if(data.messages.length === 0) {
//All good, submit the form
console.log("all good");
} else {
//Don't submit, show the user
console.log("you failed...");
}
}
});
});
});
</script>
</body>
</html>The form is pretty simple - just a textarea. Obviously a real form would have more values. Since the assumption here is that I'm validating a "snippet" of HTML, I create a 'full' doc by wrapping the form value with a doctype, html, head, and body tags. I then simply pass this to the W3C validation API. Finally, I check the results. I don't have any nice UI here, just a console dump, but let's look at some tests.
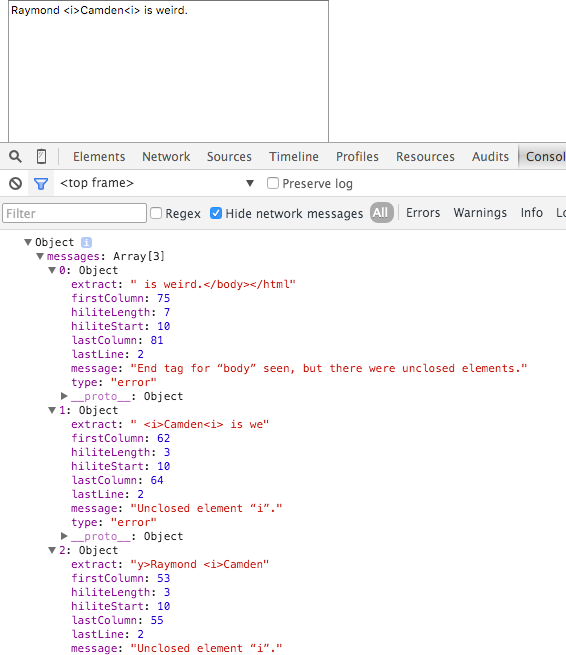
In the first test, I didn't close the italics tag correctly, and the service caught it. It reports it twice, which may be confusing, but I'd be fine with it.
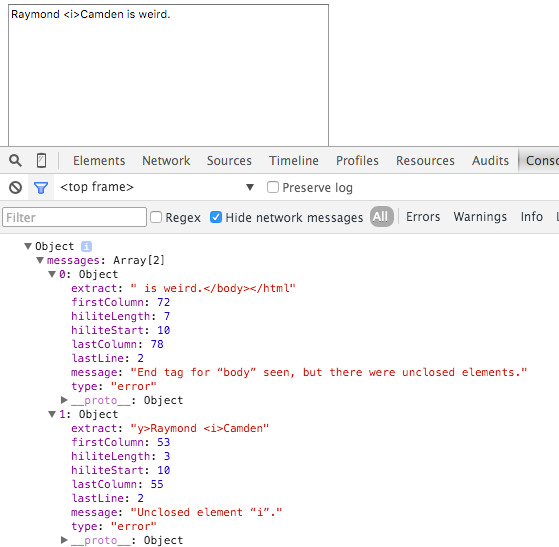
In my second test, I just left it off completely, and it was also caught.
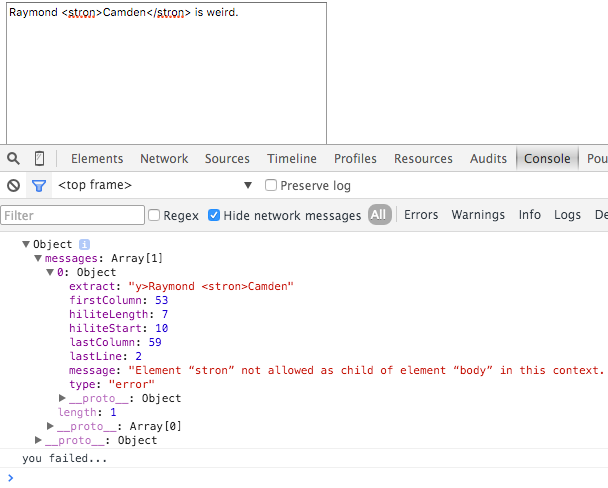
For my final test, I used proper wrapping with an unknown tag, and it also worked. Obviously this could be an issue if I'm embedding a Polymer example. (Actually, no, since it would have been escaped.)
So, what do you think? You can try a live version of this here: https://static.raymondcamden.com/demos/2015/oct/1/testjqm.html. Don't forget to open your browser developer tools of course.