Using the Marvel API with IBM Watson
A little over a year ago I blogged about my experience working with the Marvel API (Examples of the Marvel API. It's been a while since I took a look at it and I thought it might be fun to combine the Marvel data with IBM Watson's Visual Recognition service. The Visual Recognition service takes an image as input and Watson's cognitive computing/computer vision intelligence to identify different items within it.
I reviewed this service back in February in context of a Cordova app (Using the new Bluemix Visual Recognition service in Cordova). At that time, I wrote code that directly spoke to the API via code in my hybrid mobile application. For this though I wanted to make use of Bluemix and a hosted Node.js application.
My setup would be simple - let the user search against the Marvel API and return matching comic books. Since I'm planning on scanning the covers, I'd just show them:
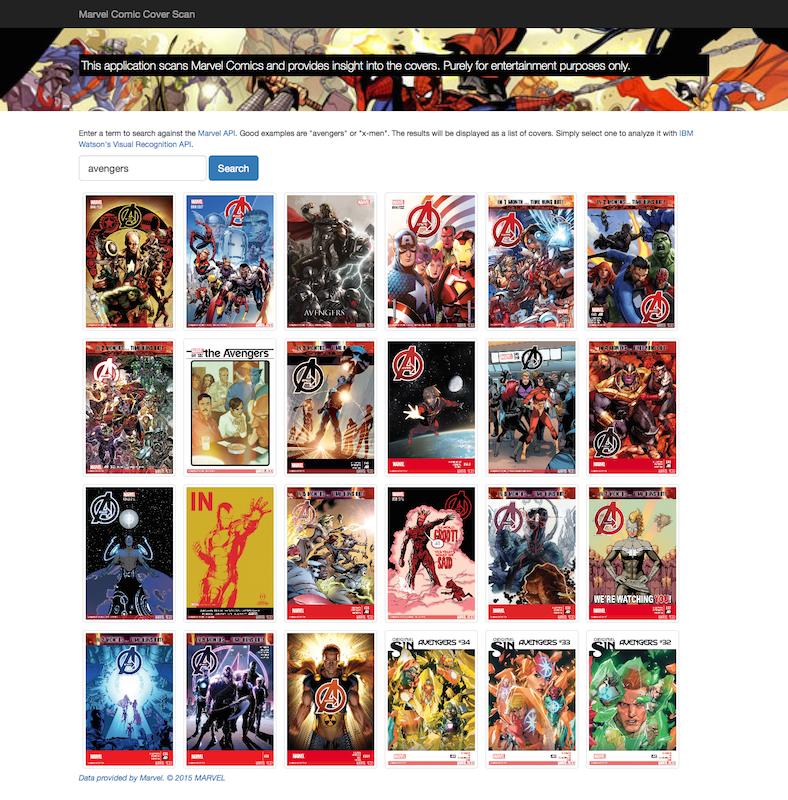
Selecting a comic will load it and then begin the call to Watson's Visual Recognition service. The service will use the cover as input and try to find things within it.
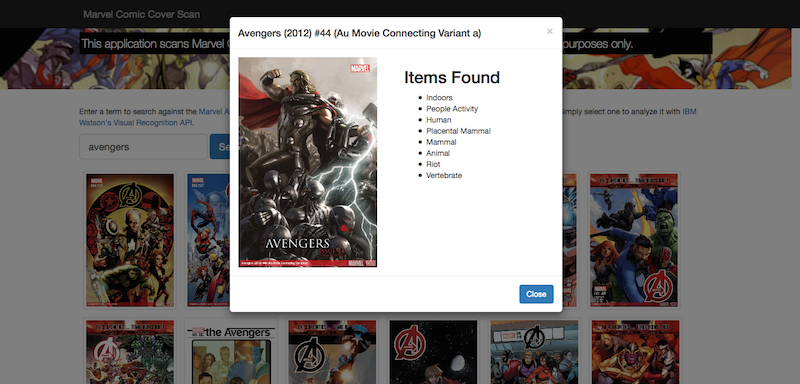
Let's take a look at the code. You can download the entire thing at my GitHub repo: https://github.com/cfjedimaster/marvelcomicrecognition. First, the main app.js:
/*jshint node:true*/
var express = require('express');
var bodyParser = require('body-parser');
var marvel = require('./marvel');
var imagerecog = require('./imagerecog');
// cfenv provides access to your Cloud Foundry environment
// for more info, see: https://www.npmjs.com/package/cfenv
var cfenv = require('cfenv');
// create a new express server
var app = express();
/*
app.engine('dust', consolidate.dust);
app.set('view engine', 'dust');
app.set('views', __dirname + '/views');
*/
app.use(express.static(__dirname + '/public', {redirect: false}));
app.use(bodyParser());
// get the app environment from Cloud Foundry
var appEnv = cfenv.getAppEnv();
// start server on the specified port and binding host
app.listen(appEnv.port, appEnv.bind, function() {
// print a message when the server starts listening
console.log("server starting on " + appEnv.url);
});
app.post('/search', function(req, res) {
var term = req.body.q;
console.log('search for '+term);
marvel.search(term,function(covers) {
res.send(covers);
});
});
app.post('/imagescan', function(req, res) {
var url = req.body.url;
console.log('scan for '+url);
imagerecog.scan(url, function(result) {
res.send(result);
});
});Of note here are the following lines:
- I've split out my Marvel and Visual Cognition code in their own files to keep my app.js nice and slim.
cfenvis a helper library for Node.js apps on Bluemix to make it easier to use environment variables and oservices.- You can see some code I commented out for Dust support. I ended up not using any template engine as my entire app was one HTML view and two Ajax calls.
- And you can see those two Ajax calls at the end. Easy-peasy.
Ok, let's look at the Marvel code. To be fair, this is pretty much the same as I built for my "random comic site" (see the first link) but modified to return all the results for a search.
/* global require,exports, console */
var http = require('http');
var crypto = require('crypto');
var cache = [];
var IMAGE_NOT_AVAIL = "http://i.annihil.us/u/prod/marvel/i/mg/b/40/image_not_available";
var cred = require('./credentials.json');
var PRIV_KEY = cred.marvel.privkey;
var API_KEY = cred.marvel.apikey;
function search(s,cb) {
var url = "http://gateway.marvel.com/v1/public/comics?limit=25&format=comic&formatType=comic&title="+s+"&apikey="+API_KEY;
var ts = new Date().getTime();
var hash = crypto.createHash('md5').update(ts + PRIV_KEY + API_KEY).digest('hex');
url += "&ts="+ts+"&hash="+hash;
console.log("url "+url);
if(s in cache) {
console.log("had a cache for "+s);
cb(cache[s]);
return;
}
http.get(url, function(res) {
var body = "";
res.on('data', function (chunk) {
body += chunk;
});
res.on('end', function() {
var result = JSON.parse(body);
var images;
if(result.code === 200) {
images = [];
console.log('num of comics '+result.data.results.length);
for(var i=0;i<result.data.results.length;i++) {
var comic = result.data.results[i];
//console.dir(comic);
if(comic.thumbnail && comic.thumbnail.path != IMAGE_NOT_AVAIL) {
var image = {};
image.title = comic.title;
for(x=0; x<comic.dates.length;x++) {
if(comic.dates[x].type === 'onsaleDate') {
image.date = new Date(comic.dates[x].date);
}
}
image.url = comic.thumbnail.path + "." + comic.thumbnail.extension;
if(comic.urls.length) {
for(var x=0; x<comic.urls.length; x++) {
if(comic.urls[x].type === "detail") {
image.link = comic.urls[x].url;
}
}
}
images.push(image);
}
}
var data = {images:images,attribution:result.attributionHTML};
cache[s] = data;
cb(data);
} else if(result.code === "RequestThrottled") {
console.log("RequestThrottled Error");
/*
So don't just fail. If we have a good cache, just grab from there
*/
//fail for now
poop;
/*
if(Object.size(cache) > 5) {
var keys = [];
for(var k in cache) keys.push(k);
var randomCacheKey = keys[getRandomInt(0,keys.length-1)];
images = cache[randomCacheKey].images;
cache[randomCacheKey].hits++;
cb(images[getRandomInt(0, images.length-1)]);
} else {
cb({error:result.code});
}
*/
} else {
console.log(new Date() + ' Error: '+JSON.stringify(result));
cb({error:result.code});
}
//console.log(data);
});
});
}
exports.search = search;And yes - poop on line 74 is my lame reminder to add proper error handling later on. Honest, I'll get to it. Now let's look at the Visual Recognition stuff:
var fs = require('fs');
var http = require('http');
var watson = require('watson-developer-cloud');
var cfenv = require('cfenv');
var appEnv = cfenv.getAppEnv();
var imageRecogCred = appEnv.getService("visual_recognition");
if(!imageRecogCred) {
var cred = require('./credentials.json');
var visual_recognition = watson.visual_recognition({
username: cred.vr.username,
password: cred.vr.password,
version: 'v1'
});
} else {
var visual_recognition = watson.visual_recognition({
version: 'v1',
use_vcap_services:true
});
}
var cache = {};
function scan(url, cb) {
//create a temp file name based on last 3 items from url: http://i.annihil.us/u/prod/marvel/i/mg/a/03/526ff00726962.jpg
var parts = url.split("/");
var tmpFilename = "./temp/" + parts[parts.length-3] + "_" + parts[parts.length-2] + "_" + parts[parts.length-1];
if(tmpFilename in cache) {
console.log('image scan from cache');
cb(cache[tmpFilename]);
return;
}
// download file then we can use fs.createReadableStream
var file = fs.createWriteStream(tmpFilename);
http.get(url, function(response) {
response.pipe(file);
file.on('finish', function() {
file.close();
var params = {
image_file: fs.createReadStream(tmpFilename)
};
visual_recognition.recognize(params, function(err, result) {
if (err) {
console.log("visual recog error",err);
cb({"error":1})
} else {
//console.log(JSON.stringify(result));
var tags = [];
for(var i=0; i<result.images[0].labels.length; i++) {
tags.push(result.images[0].labels[i]);
}
cache[tmpFilename] = tags;
cb(tags);
}
});
});
});
}
exports.scan = scan;I made use of the Watson Developer Cloud npm package to speak to the service. For the most part this makes it easy, but right now it expects a physical file. (I mentioned this and the team behind it is already working on improving this.) So to make it work I had to download the file from the Marvel API and then send it up to Watson. I don't have "cleanup" code yet, but it gets the job done. As I said, once the Watson team adds support to talk to a URL, nearly half of this code will go away.
For the final part, here is the JavaScript I use on the front end:
var $searchField;
var $resultDiv;
var $modal;
var $coverImage;
var $recogStatus;
var $modalTitle;
var $searchBtn;
$(document).ready(function() {
$searchField = $("#searchField");
$resultDiv = $("#results");
$modal = $("#coverModal");
$coverImage = $("#coverImage");
$recogStatus = $("#recogStatus");
$modalTitle = $(".modal-title",$modal);
$searchBtn = $("#searchBtn");
$searchBtn.on("click", handleSearch);
$("body").on("click","#results img",doCover);
});
function handleSearch(e) {
e.preventDefault();
var value = $.trim($searchField.val());
if(value === '') return;
$searchBtn.attr("disabled","disabled");
console.log('ok, lets search for '+value);
$resultDiv.html("<i>Searching...</i>");
$.post("/search", {q:value}, function(res) {
//result is an array of cover images
var s = "";
if(res.images.length) {
for(var x=0;x<res.images.length;x++) {
s += "<img src='" + res.images[x].url + "' title='" + res.images[x].title + "' class='img-thumbnail'>";
}
s += "<p><i>"+res.attribution+"</i></p>";
} else {
s = "<p>Sorry, but there were no matches.</p>";
}
$resultDiv.html(s);
$searchBtn.removeAttr("disabled");
});
}
function doCover(e) {
//default loading msg
var loadingMsg = "<i>I'm now sending this image to the Bluemix Image scanner. Millions of little baby kittens are running on little treadmills to power the machine behind this scan. I hope you appreciate it!</i>";
var title = $(this).attr("title");
var src = $(this).attr("src");
$modalTitle.text(title);
$coverImage.attr("src",src);
$recogStatus.html(loadingMsg);
$modal.modal('show');
$.post("/imagescan", {url:src}, function(res) {
var s = "<ul>";
for(var i=0;i<res.length;i++) {
s += "<li>" + res[i].label_name + "</li>";
}
s += "</ul>";
$recogStatus.html(s);
},"JSON");
}Nothing too terribly interesting here besides some basic jQuery DOM manipulation. If any of this doesn't make sense, just let me know, but obviously the heavy lifting here is really being done on the back end.
So what else is there? As I said, this is all hosted on Bluemix. I've blogged about Bluemix and Node.js apps before, but in case your curious about the process...
- Create a new app with Bluemix and select the Node.js starter.
- Add the Visual Recognition service.
- If you haven't installed the command line, do it one time.
The entire process is roughly five minutes. I can then use the command line to push up my code to Bluemix. You can see the final app yourself here: http://marvelcomicrecognition.mybluemix.net/.