Building an HTML5 Comic Book Reader
Edited on February 17, 2013: I was alerted by a reader that this code is broken now. To fix the bug I needed to make one code tweak (noted below) and update to the latest copy of zip.js.
Following up on my Sunday blog post on comics, I thought it would be fun to share a little experiment I built this weekend. Comic books are available in a compressed format typically called CBRs or CBZs. These aren't a special format, just simple compressed archives. CBRs are RAR files and CBZs are zips. While there doesn't appear to be good support for RAR files (I've only found a Java library to list the contents), the Zip format is much more widely used and easy to work with. In fact, you can find an excellent JavaScript implementation: zip.js I thought it might be fun to try using that to build my own web-based CBZ reader. Here's how I did it.
First, I added drag/drop support to my application so that users could simply drag in their local CBZ files. Instead of a div, I made the entire page a target for drop events:
Edit on February 17, 2013: Chrome recently changed something (or changed after I blogged) that now makes you listen for, and prevent, the dragover event. This is a very minor update:
The dropHandler needs to do a few things. First - it needs to figure out the type of drop. Don't forget that people can drag/drop blocks of text from other applications. What I want is to listen for files. Even better - I need to ensure that one file is dropped, not multiple. Here's the snippet for that logic.
Ok, now for the fun part. My application needs to try to decompress the zip file to the file system. In order to do that I am making use of the HTML5 File API. Earlier on I did a quick request for some temporary file storage - which is pretty simple:
Having the file system means I can extract the images out of the zip into the directory and refer to them later. We have access to the file from the drop event, so it is a simple matter of:
- Pass the file data to zip.js
- Extract the files
- Save the files (again, this is a temporary file system)
- Store a reference to them so I can display them to the user
Here is the function that handles all of that.
Once done - that leaves us with the simple job of providing basic interaction with the images. This is done via buttons that allow for navigation.
And that's it! Before I link to the demo, I'll warn you that this is not very tolerant of browsers that don't support everything required. Here are a few screen shots though to give you an idea of how it works.
First up - the application as it looks on loading.
Next - I drag a CBZ file over it...

And then it gets to work. Now - this part can be a bit slow. To be fair, I dragged a 35 megabyte file into the browser and it took about 40 seconds to parse. I think that's fairly decent for JavaScript.

I also provide UI feedback as the images are saved.
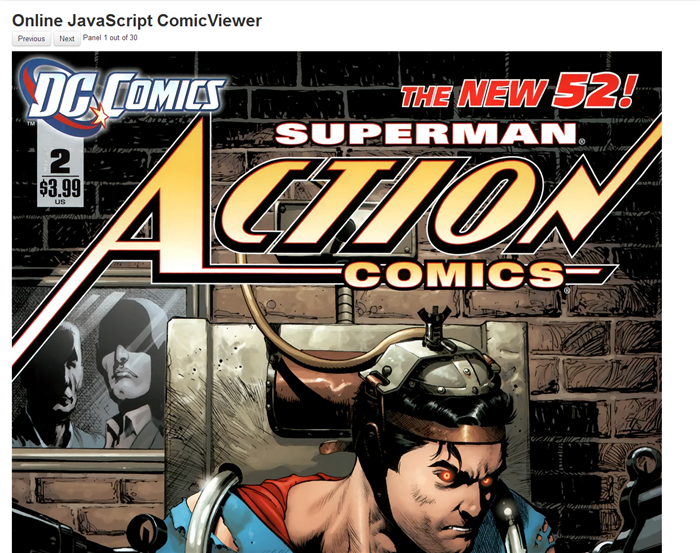
And then finally - the comic is readable. (Whether or not the story is any good is another question.)
Want to try it out? Hit the demo link below. Note that you may want to try with the latest Chrome and with a small comic. I've created a simple "comic" out of a zip of pictures that can be downloaded here.
Edit on 2/2/2018: Due to the age of the demo, and the fact that the File API is deprecated, I've removed the online demo. You can still download the code, but I would not recommend using it as is. Rather, you could unzip the binary data into IndexedDB. You can download the code here: https://static.raymondcamden.com/enclosures/2012_05_28.zip