Building a Comic Book Reader in BoxLang

I've been a comic book reader for just about the same amount of time as I've been writing code. Any computer using comic book reader (and there's probably quite a few) will know that electronic versions of comics let you read comics on your devices. These comics typically come in one of two formats, CBR and CBZ, which are literally just RAR and ZIP files, nothing more. Over the years, I've had fun building my own web-based readers for this format, with my last one from a bit over three years ago, "Reading Comic Books in the Jamstack". I thought it would be fun to tackle this in BoxLang and see what worked well and what proved difficult. I've got a complete demo done that I'll link to at the end, but let's dig into what I created.
Working with Zip and RAR Files in BoxLang
Let's tackle the easy one first - zip files. BoxLang has native support and I blogged some examples of that a few months ago. So that parts done. Sweet.
RAR is... problematic. Every time I work with RAR it's a problem.

My Googling for Java RAR solutions led to a few places, mostly abandoned code, but finally, a repo with a bit of life at https://github.com/junrar/junrar. It took me a little to get this working in BoxLang, mostly because I was fumbling around a bit with the Jars and trying to parse the documentation, but eventually got a simple use case working:
junRar = new com.github.junrar.Junrar();
junRar.extract(pathToComic, exportDir);
The junrar sdk supports more operations than that, but honestly that's all I needed.
The Process
Ok, so now comes the complicated part. My plan is to build a web application that lets readers view available comics:
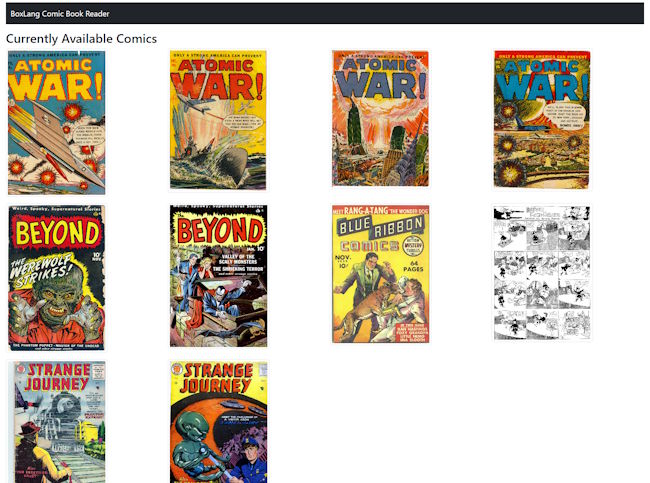
Clicking a comic than loads the first page, with buttons to go to the next (and after clicking once) and previous pages:

One possible way to build this would be to read in the comic and parse out the image on every request. While that would work, it would be horribly inefficient. Instead, I built a system that scans for comics, determines which need to be extracted, and then only extracts the newer ones. It will also handle creating the thumbnail seen in the screenshot above.
Most of this logic is done with a comic class named comic.bx. First, I built a method to return "available" comics, these are comics that have been extracted with a thumbnail created.
// earlier in the code comicSource and cacheSource are defined:
property name="comicSource" type="string";
property name="cacheSource" type="string";
public function getAvailableComics() {
comics = [];
// first get our source
srcComics = directoryList(comicSource);
// now for each, we require at least one page in cache/slugify(filename) to be available (one file being __thumb)
for(comic in srcComics) {
// get the slugified name
slug = slugify(getFileFromPath(comic));
// check if we have a thumbnail in the cache
if(fileExists(cacheSource & "/" & slug & "/__thumb.jpg")) {
// add to our list
images = directoryList(path=cacheSource & "/" & slug, recurse=true, filter=(path) => {
return getFileInfo(path).type == "file" && isImageFile(path);
});
comics.append({
"name": GetFileFromPath(comic),
"slug": slug,
"thumbnail": "/comiccache/" & slug & "/__thumb.jpg",
"images":images
});
}
}
return comics;
}
Basically, get all the files in the source directory and check the cache. The cached, extracted comic will be stored in a directory based on the filename, ran through a slugify function. I check for the existence of a thumbnail as my marker that the comic is ready. I then proceed to get the images and add the result to my array of available comics.
The directoryList filter is important. What I found when extracting comics from my samples is that every one extracted to a subdirectory named for the comic with images underneath that. So my directoryList uses recurse=true to get everything from the root of the cache for the comic and then filter to images.
Next, I built a function to handle processing new comics:
public function scanForNewComics() {
srcComics = directoryList(comicSource);
processedComics = getAvailableComics();
for(comic in srcComics) {
println("Processing comic: " & comic);
if(processedComics.find(c => c.name == GetFileFromPath(comic)) == 0) {
println('this comic needs to be done');
// where I'll save
exportDir = cacheSource & "/" & slugify(getFileFromPath(comic));
directoryCreate(exportDir, true, true);
/*
ok, here comes the fun part. first, determine type
I discovered some .cbr files are actually zips - isZipFile worked on it
*/
ext = comic.listlast('.').toLowerCase();
if(ext === 'cbz' || isZipFile(comic)) {
extract(format='zip', source=comic, destination=exportDir, overwrite=true);
} else if(ext === 'cbr') {
junRar = new com.github.junrar.Junrar();
junRar.extract(comic, exportDir);
}
// now we get the first image so we can make a thumbnail
firstImage = directoryList(path=exportDir,recurse=true, filter=(path) => {
return getFileInfo(path).type == "file" && isImageFile(path);
}).first();
img = imageRead(firstImage);
img.scaleToFit(250, 250);
img.write(expandPath(exportDir & '/__thumb.jpg'));
}
}
}
Essentially - get all of the comics in the source, compare to those that are already processed, and process the remaining ones. Now, I think for the most part this makes sense, basically use the built-in zip extraction for CBZ files and the junrar library for CBR files, but in my testing, I kept getting an error on a few CBR files. I dug up a Windows app, I think 7Zip, to look at the file and discovered that despite having a CBR extension, it was actually a zip file! Hence the OR in this condition:
if(ext === 'cbz' || isZipFile(comic)) {
Honestly I could probably get rid of the first clause I suppose, but I do like that I can read the intent better.
After the images are extracted, I grab the first image and create a thumbnail from it.
Now, one important question is - when should this code run? There's multiple options that would work:
- On a schedule, using BoxLang's scheduled tasks support.
- In an admin system of some sort, it could be kicked off manually.
- When the application starts up.
I took the final approach, and you can see it in my Application.bx onApplicationStart method:
public function onApplicationStart() {
application.comicSource = expandPath('./comics');
application.comicCache = expandPath('./comiccache');
if(!directoryExists(application.comicSource)) {
throw(message="Comic source directory does not exist: " & application.comicSource);
}
if(!directoryExists(application.comicCache)) {
createDirectory(application.comicCache);
}
application.comics = new classes.comics(comicSource=application.comicSource, cacheSource=application.comicCache);
// On startup, kick off the process to scan for new comics to parse.
application.comics.scanForNewComics();
}
Of course, you could imagine using all three approaches in an application.
The Rest of It...
The rest of the application is fairly simple. I'm using Bootstrap for the UI which kept the design rather basic. The home page handles getting and displaying the available comics:
<bx:script>
comics = application.comics.getAvailableComics();
</bx:script>
<bx:component template="components/layout.bxm" title="BoxLang Comic Book Reader">
<h2>Currently Available Comics</h2>
<div class="row row-cols-4">
<bx:loop array="#comics#" index="comic">
<div class="col">
<bx:output>
<p>
<a href="comic.bxm/#comic.slug#"><img src="#comic.thumbnail#" alt="#comic.name#" class="img-thumbnail"></a>
</p>
</bx:output>
</div>
</bx:loop>
</div>
</bx:component>
Notice I'm passing the comic slug via the URL to the template that handles rendering comics. That one is a bit more complex as it needs to look at the URL to see which image to display:
<bx:script>
if(cgi.path_info.trim().len() === 0) {
bx:location url="/";
} else slug = cgi.path_info.trim().replaceAll("/", "");
try {
comic = application.comics.getComicBySlug(slug);
} catch(e) {
bx:location url="/";
}
bx:param name="url.image" default="1";
url.image = int(url.image);
if(url.image < 1 || url.image > comic.images.len()) {
url.image = 1;
}
img = imageRead(comic.images[url.image]);
</bx:script>
<bx:component template="components/layout.bxm" title="BoxLang Comic Book Reader - #comic.name#">
<bx:output>
<h2>#comic.name# (Page #url.image# of #comic.images.len()#)</h2>
<div class="container">
<div class="row justify-content-center">
<bx:saveContent variable="nav">
<div class="btn-group" role="group">
<a class="btn btn-primary <bx:if url.image is 1>disabled</bx:if>" href="/comic.bxm/#comic.slug#?image=#url.image-1#">Previous</a>
<a class="btn btn-primary" href="/comic.bxm/#comic.slug#?image=#url.image+1#">Next</a>
</div>
</bx:saveContent>
#nav#
<!---
Currently bugged...
<bx:image action="writeToBrowser" source="#comic.images[url.image]#" class="img-fluid">
--->
<div>
<img src="data:image/jpg;base64,#imageWriteBase64(img,'jpg')#" class="img-fluid" alt="#comic.name#">
</div>
#nav#
</div>
</div>
</bx:output>
</bx:component>
From the top, I first validate a comic was passed in the path, available via cgi.path_info. This calls a simple utility method in my class:
public function getComicBySlug(slug) {
comics = getAvailableComics();
return comics[comics.find(c => c.slug == slug)];
}
I'll note that getAvailableComics could be, should be, modified to cache its results. Anyway, back to the template. After validating a proper comic was requested, I then check for image in the URL, defaulting it to 1. I validate the value is a number and within a valid range.
Inside the template, I made use bx:saveContent to store my simple button nav to a variable so I could use it twice on the page, once on top and once on the bottom.
To render the image, there is a method to handle doing that including outputting the HTML, writeToBrowser, but it's currently bugged for me so I simply converted it to base64. The comic cache actually lives under my web root, but I imagined in a real world situation it would not. Simply pointing directly to it would also be a perfectly valid option.
All in all, a fun little diversion from more serious work, and if your curious, you can find thousands of legal electronic comics at Comic Book+https://comicbookplus.com/). Finally, you can find the complete repo for this demo here: https://github.com/ortus-boxlang/bx-demos/tree/master/webapps/comicreader